
개요
이번엔 좀 빠릿빠릿하게 써보려고 합니다.
바로 저번주에 나갔던 진도를 지금 적겠습니다.
이렇게 말하면 달라진게 없는 것 같은데 '저번 주 목요일'에 나갔던 진도를 '이번 주 월요일'에 정리하는거니까 따지고보면 빠릿빠릿한거겠죠???
사실 진도는 배열과 벡터였는데 저번 글에 이미 배열을 적었더라구요?
그래서 같이 나간 벡터와 반복자를 다뤄보겠습니다.
벡터란?
수학적으로도 물리적으로도 제가 했던 유니티에서도 벡터는 힘과 방향이였습니다.
근데 C++에선 C#의 List와 비슷한 자료구조 입니다.
vector와 List 둘 다 크기가 유동적으로 늘어나는 특징을 가지고 있습니다.
그리고 vector와 List의 데이터 할당 방식에서 vector와 list가 자신의 크기를 미리 정할 수 있게 해주는 이유를 알 수 있습니다.
vector는 자신의 크기를 초과하는 양의 데이터를 받았을때
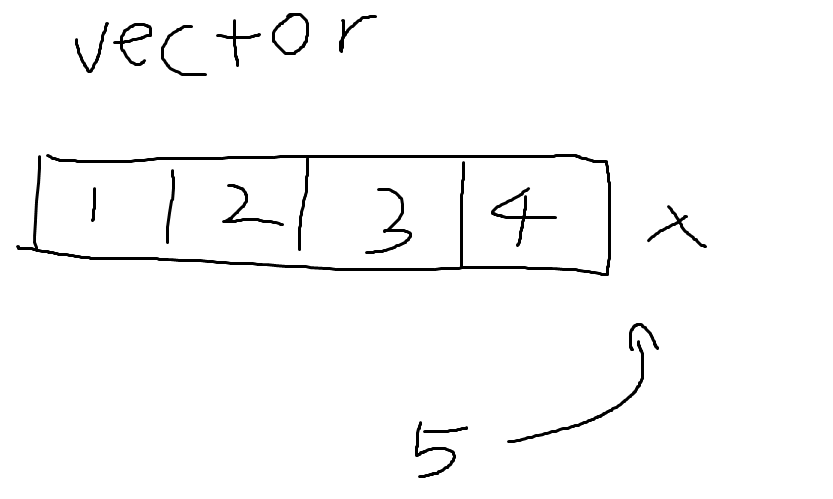
크기를 약 1.5배 정도 늘리고 그 크기 만큼의 데이터 공간을 만들어 자신의 안에 있던 데이터들을 그대로 그 곳에 복사한 뒤 예전에 있던 곳을 삭제하고 거처를 옮깁니다.
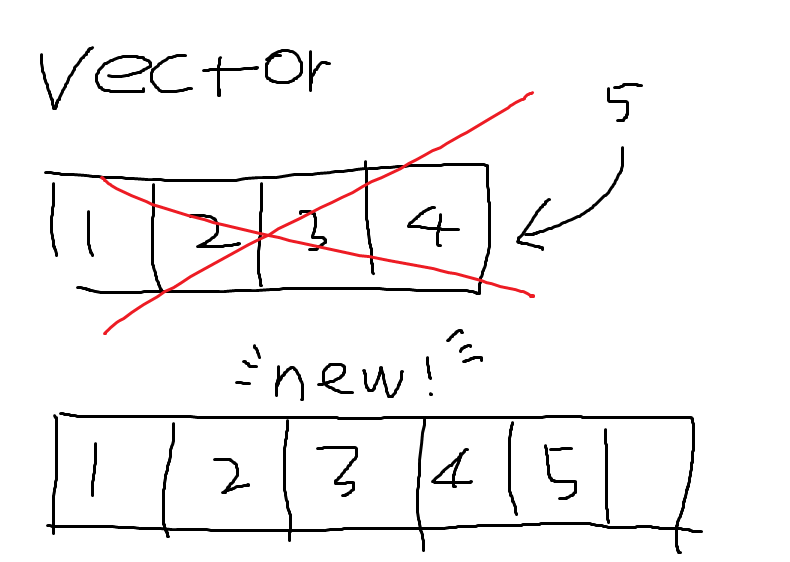
이 방식이 안좋은 이유가 vector의 값이 자주 늘어나면 계속해서 값을 복사해야하기 때문에
성능에 문제가 생깁니다.
그래서 지원하는게,
복사 비용 줄이기
vector.reserve()와 vector.resize() 입니다.
이 함수 두개를 사용해 복사가 일어날 일을 줄일 수 있습니다.
reserve()
reserve는 vector의 크기를 미리 정해주는 함수입니다.
그냥 vector의 처음 크기를 매개변수로 넣어주는 값 만큼 사용하겠다는 뜻입니다.
그렇기 때문에 실 사용중인 크기인 size는 변화하지 않습니다.
vector<int> v;
v.reserve(1000); // vector의 크기가 1000이 됐음
v.push_back(1); // 0번째 인덱스에 값이 삽입됨
resize()
resize는 reserve와 비슷하지만 다릅니다.
실 사용중인 크기인 size가 resize에 넣어주는 매개변수 까지 증가합니다.
vector<int> v;
v.reserve(1000); // vector의 크기가 1000이 됐음
v.push_back(1); // 1000번째 인덱스에 값이 삽입됨
이런 함수들을 사용하면 vector의 값이 복사되는 일을 줄일 수 있습니다.
반복자
반복자라... 이름부터 맘에 안듭니다.
'반복'자? 하지만 반복하는 놈이 아니라 포인터라고 봐도 무방합니다.
벡터나 배열과 달리 [i] 같이 인덱스 접근이 불가능한 자료구조들에게 접근하기 위해 사용합니다.
가장 많이 쓰는 것들은 begin()과 end() 입니다.
begin은 가장 첫번째 원소의 주소, end는 가장 마지막 원소의 주소 + 1을 반환합니다.
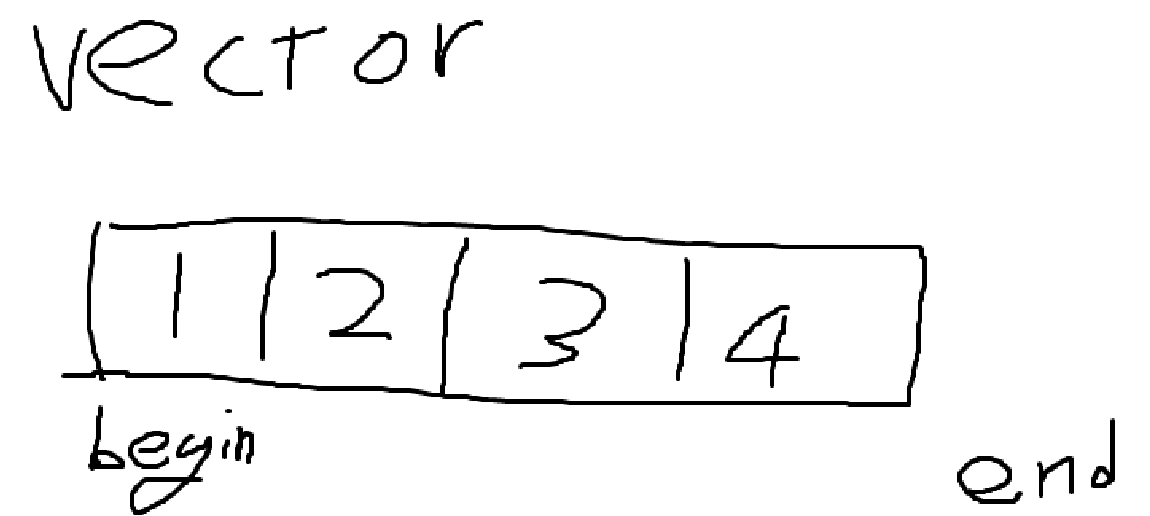
반복자는 vector<int> :: iterator it; 같이 선언합니다.
반복자 변수엔 아까 말했던 begin이나 end같은 주소나 find같은 함수로 찾아온 주소를 담을 수 있습니다.
사실 아직 포인터나 반복자나 거기서 거기같아요.
이러한 특성으로 인해 반복자는 for문에서 맛있게 사용할 수 있습니다.
vector<int> v;
vector<int> :: iterator it;
for(it = v.begin(); it < v.end(); ++it)
{
cout << *it;
}와 같이 말이죠.
마치는 말
벡터는 유동적인 크기라는 점 때문에 자주 쓰입니다.
근데 저에겐 아직 겜프시간에 배운 동적배열이 남아있죠.
반복자에 대해선 사실 반정도 이해했습니다. 말로 풀어쓰기가 어려울 뿐이죠.